Technical Deep Dives
Partitioning a 2-Bil-Row Table: Why the Base Table Still Won#
Overview
The Question
I evaluated whether an expenses table approaching approximately two billion rows should be migrated to a native MySQL partitioned design. Using production-shaped data and real workloads, I tested multiple partitioning strategies, composite index designs, and primary key orderings.
The Outcome
The outcome was not that partitioning failed. Instead, the testing showed that even under aggressive optimization, the existing unpartitioned table remained highly competitive and, in several cases, superior. Based on these results, I chose to defer partitioning.
Background: Year-Based Tables
The Previous Approach
Prior to this work, we used separate year-based tables such as expenses_2022 and expenses_2023 as a form of unofficial partitioning. While workable at smaller scale, this approach introduced increasing operational costs.
Operational Challenges
- Applications required complex query logic to support cross-year access
- Schema changes had to be coordinated across multiple tables
- MySQL could not perform native partition pruning, which forced manual routing logic in application code
- Over time, this also increased the risk of schema drift
The Opportunity
Native partitioning was an attractive alternative if it could deliver both performance improvements and operational simplicity.
What I Tested
Test Setup
Using approximately twenty million rows per table and representative users with roughly twenty-two thousand rows each, I benchmarked the following:
Test Configurations
- The original unpartitioned table
- Year-partitioned tables with optimized composite indexes
- Multiple primary key orderings, including
(year, transaction_id)and(transaction_id, year) - Mixed workloads including user-scoped reads, multi-year date range queries, complex filters, bulk and individual
UPDATEs, and sequentialINSERTs
Measurement Methodology
All tests were run with warm caches and measured using EXPLAIN ANALYZE.
Key Result
Overall Finding
Partitioning did not produce a clear, across-the-board performance improvement.
Detailed Analysis
Even with year-based partition pruning, carefully tuned composite indexes, and alternative primary key orderings, the unpartitioned table consistently performed within the same range and often performed better for critical queries.
Where the Base Table Remained Competitive
User- and Date-Scoped SELECTs
For the dominant access pattern, user-scoped reads over date ranges, the base table was either faster or within ten to twenty milliseconds of the best-performing partitioned variant. Strong indexing on (user_id, date) significantly reduced the theoretical advantage of partition pruning.
UPDATE Operations
UPDATE performance provided the strongest signal. One partitioned configuration degraded UPDATE operations from milliseconds to more than thirty seconds. Even the safer partitioned variants showed no meaningful improvement over the base table. The unpartitioned table remained predictable and stable under write load.
Key Insight
This reinforced an important conclusion: A well-indexed unpartitioned table can outperform a partitioned table with an imperfect primary key, even at large scale.
INSERT Workloads
Sequential ingestion performance was comparable across all configurations. Partitioning did not provide a material advantage, and the base table handled sustained inserts without issue.
Decision
The Conventional Wisdom
Partitioning is often treated as an obvious scalability step. In this case, the data showed otherwise.
What the Data Showed
- Index design had a larger impact on performance than partitioning
- Primary key ordering introduced meaningful risk
- The existing table already exhibited strong and predictable performance characteristics
- Partitioning added new failure modes without delivering clear gains
The Decision
Given these tradeoffs, I deferred partitioning because it was not justified by measured results.
Conclusion
Summary
After testing optimized composite indexes, multiple partitioning strategies, and different primary key orderings, the original unpartitioned table remained competitive, stable, and predictable.
Future Considerations
Partitioning remains a viable future step. It will be revisited once it offers clear and measurable advantages over a well-designed base table.
Production-Safe Large-Scale Data Migration (≈693M Rows)#
Overview
I designed and executed a zero-downtime, production-safe migration to consolidate two year-partitioned transaction tables (expenses_2022, expenses_2023) into a single archive table (~693M rows total).
Rather than a one-off script, the migration was built as a self-regulating system: resumable, adaptive under load, observable in real time, and capable of safely shutting itself down if it threatened production stability. The system was designed to tolerate partial runs, retries, and duplicate data without requiring manual intervention.
Key Design Decisions
Colocated Execution (VM + Database)
The migration ran on a dedicated VM deployed in the same GCP region and zone as the CloudSQL instance. This was a deliberate colocation choice to:
- minimize network latency
- avoid cross-zone egress costs
- maximize sustained throughput for long-running batch operations
Cursor-Based Pagination (Date-Driven, Monotonic)
Instead of OFFSET pagination or repeated COUNT queries (which degrade badly at scale), the migration uses a monotonic, date-based cursor. Completion is determined by exhausting the source cursor, not by matching row counts.
This avoids full table scans and keeps batch performance stable as the dataset grows.
-- cursor-based pagination
SELECT date
FROM expenses_2023 USE INDEX (date_index)
WHERE date > :lastDate
ORDER BY date ASC, transaction_id ASC
LIMIT :batchSize;To prevent silent infinite loops, the system explicitly detects cursor stagnation and fails fast:
const upperBound = result[result.length - 1]?.date;
if (upperBound === lastDate) {
throw new Error('Cursor stagnation detected – aborting to prevent infinite loop');
}Failing fast here is intentional and safer than continuing indefinitely.
Idempotent, Resume-Safe Writes
All batch inserts use INSERT IGNORE, enabling safe re-runs and mid-batch resumes without risking duplicate data or manual cleanup. Duplicates are expected due to resumability and prior partial runs, and are handled intentionally.
INSERT IGNORE INTO expenses_combined_archive (...)
SELECT ...
FROM expenses_2022
WHERE date > :lastDate AND date <= :upperBound
ORDER BY date ASC, transaction_id ASC;This design guarantees:
- idempotency
- safe restarts
- tolerance of partial failures
Adaptive Batch Sizing (Throughput-Driven)
Batch sizes dynamically scale based on observed rows/sec, allowing the system to push harder when conditions are good and back off under contention.
if (avgRowsPerSecond < 1000) {
batchSize = Math.max(batchSize * 0.7, MIN_BATCH_SIZE);
} else if (avgRowsPerSecond > 3000) {
batchSize = Math.min(batchSize * 1.5, MAX_BATCH_SIZE);
}This avoids hard-coded batch assumptions and keeps CPU utilization high without overwhelming the database.
Lock-Aware Execution with Bounded Retries
All reads and writes are wrapped with explicit lock timeouts and retry logic. Deadlocks and lock waits are treated as expected behavior at scale, not fatal errors.
Retries are bounded to prevent runaway contention.
async function executeWithRetry<T>(operation: () => Promise<T>): Promise<T> {
for (let attempt = 0; attempt < 3; attempt++) {
try {
return await db.transaction(async (tx) => {
await tx.query('SET innodb_lock_wait_timeout = 5');
return await operation();
});
} catch (error) {
if (isLockError(error) && attempt < 2) {
await sleep(100 * (attempt + 1));
continue;
}
throw error;
}
}
throw new Error('Max retries exceeded');
}Automated Kill Switch with Early Warning
The migration continuously monitors:
- process CPU and memory
- system memory
- database connection pool usage
- disk growth relative to a detected baseline
CloudSQLCPU and memory- error rates and query timeouts
Slack warnings are sent before thresholds are reached. If a hard limit is exceeded, the system performs a safe shutdown:
if (cpu > MAX_CPU || memoryMB > MAX_MEMORY || errorRate > MAX_ERROR_RATE) {
saveResumeState();
flushFileOperations();
process.exit(130); // safe, resumable shutdown
}Resume state is written atomically to avoid corruption:
fs.writeFileSync(tempFile, JSON.stringify(state));
fs.renameSync(tempFile, resumeStateFile);This ensures the migration can resume exactly where it left off with no data loss.
Post-Load Index Creation (Separate Phase)
Indexes are created after data loading, sequentially, with:
- preflight existence checks
- session-level timeout tuning
- retries
- cooldown pauses between indexes
CREATE INDEX idx_expenses_user_date ON expenses_archive(user_id, date);
SELECT SLEEP(60);Stripe Legacy Plan Migration#
Production-safe subscription migration with validation, reconciliation, and observability
Overview
I designed and executed a zero-downtime migration to move active subscribers from legacy Stripe price IDs to new plans in production. Because billing changes are irreversible and high-risk, the migration was built as a self-guarding operational system, not a one-off script.
The result was a controlled rollout that preserved billing continuity, respected coupon contracts, and produced auditable reconciliation artifacts before and after execution.
Problem
Legacy Stripe prices were still attached to live subscriptions while new pricing had already shipped across application code and infrastructure. Migrating these subscribers required handling:
Striperate limits and transient API failures- Subscriptions changing state mid-migration
- Contractual coupon constraints
- The risk of operator error in production environments
A naive migration risked incorrect charges, broken subscriptions, or silent data drift.
Solution
I implemented a migration pipeline with safety and observability designed in from the start.
Preflight Safety Gates
The script blocks execution unless all prerequisites are verified: correct environment, deployed infra (Terraform + Kubernetes), valid price mappings, and required database records.
Rate-Limited, Retry-Safe Stripe Updates
All Stripe writes are serialized, throttled well below account limits, wrapped in timeouts, and retried with exponential backoff.
const stripeUpdateQueue = new PQueue({
concurrency: 1,
intervalCap: 1,
interval: 80
});Billing-Safe Updates
Subscriptions are migrated using item-level updates with proration_behavior: 'none', ensuring no surprise charges and safe re-runs.
Explicit Coupon Policy Handling
Coupons are treated as first-class constraints:
- A specific referral coupon is allowed and migrated
- All other coupons are intentionally skipped, logged, and tracked
Deterministic Reconciliation
Before and after the migration, the script produces:
Stripesubscription counts by status- Database subscription counts by status
- An intersection view to surface mismatches between systems
Operational Traceability
Each run emits per-plan logs, a master summary, structured failure breakdowns, and analytics events for post-migration monitoring.
Outcome
- Migrated legacy subscriptions with zero downtime or billing regressions
- Prevented production execution unless infra and configuration were correct
- Generated auditable reconciliation artifacts and follow-up workflows
- Established a repeatable pattern for future
Stripeplan migrations
Why This Matters
Billing migrations fail most often due to hidden state, operator error, or lack of observability. This project demonstrates how to treat high-risk data changes as controlled production operations—with guardrails, proofs, and clear exit paths.
Churn & Retention Flow Implementation#
Implementing a product-designed retention funnel in a billing-critical system
Context
Product redesigned our churn experience to move beyond a simple cancellation survey and introduce reason-based retention paths. Implementing this safely was non-trivial. Churn touches billing, refunds, lifecycle state, analytics, and user messaging, and mistakes here are costly.
My role was to implement the product-designed flow end to end, ensuring correctness across Stripe, backend state, and analytics.
What I Implemented
I implemented a reason-driven churn funnel backed by centralized cancellation logic.
My scope included:
- Translating product designs into a deterministic frontend flow
- Enforcing eligibility rules to prevent invalid retention offers
- Centralizing cancellation behavior to avoid
Stripeand database drift - Ensuring analytics and lifecycle state remained consistent

Frontend Implementation
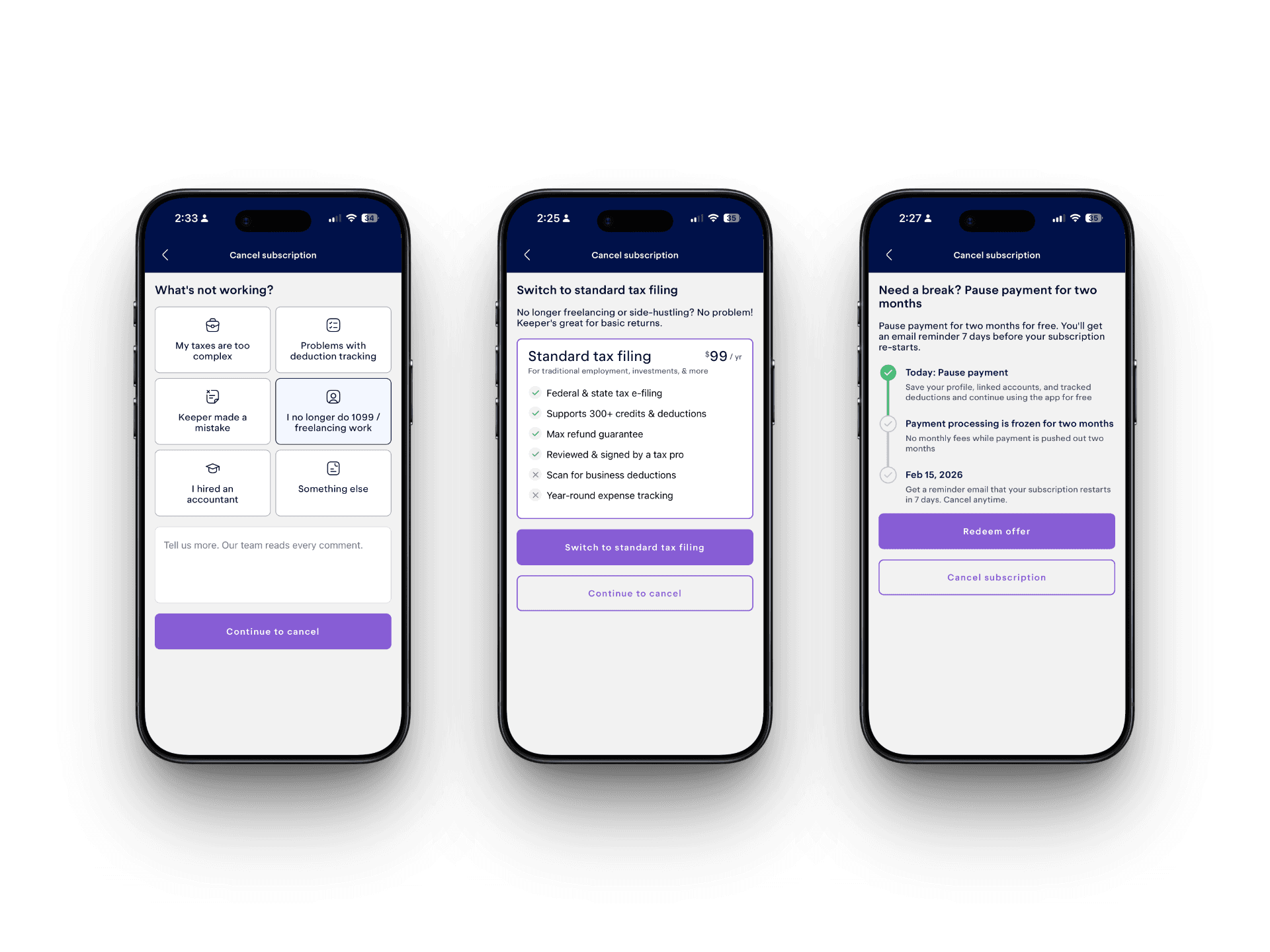
Cancellation Survey
Users enter the flow from Settings → Manage Subscription.
The survey collects a cancellation reason defined by product. Each reason deterministically routes to either a retention screen or direct cancellation.
Key implementation details:
- Reasons shuffled to reduce bias
- Optional free-text feedback
- Continue button disabled until a reason is selected
- No forced loops or dark patterns
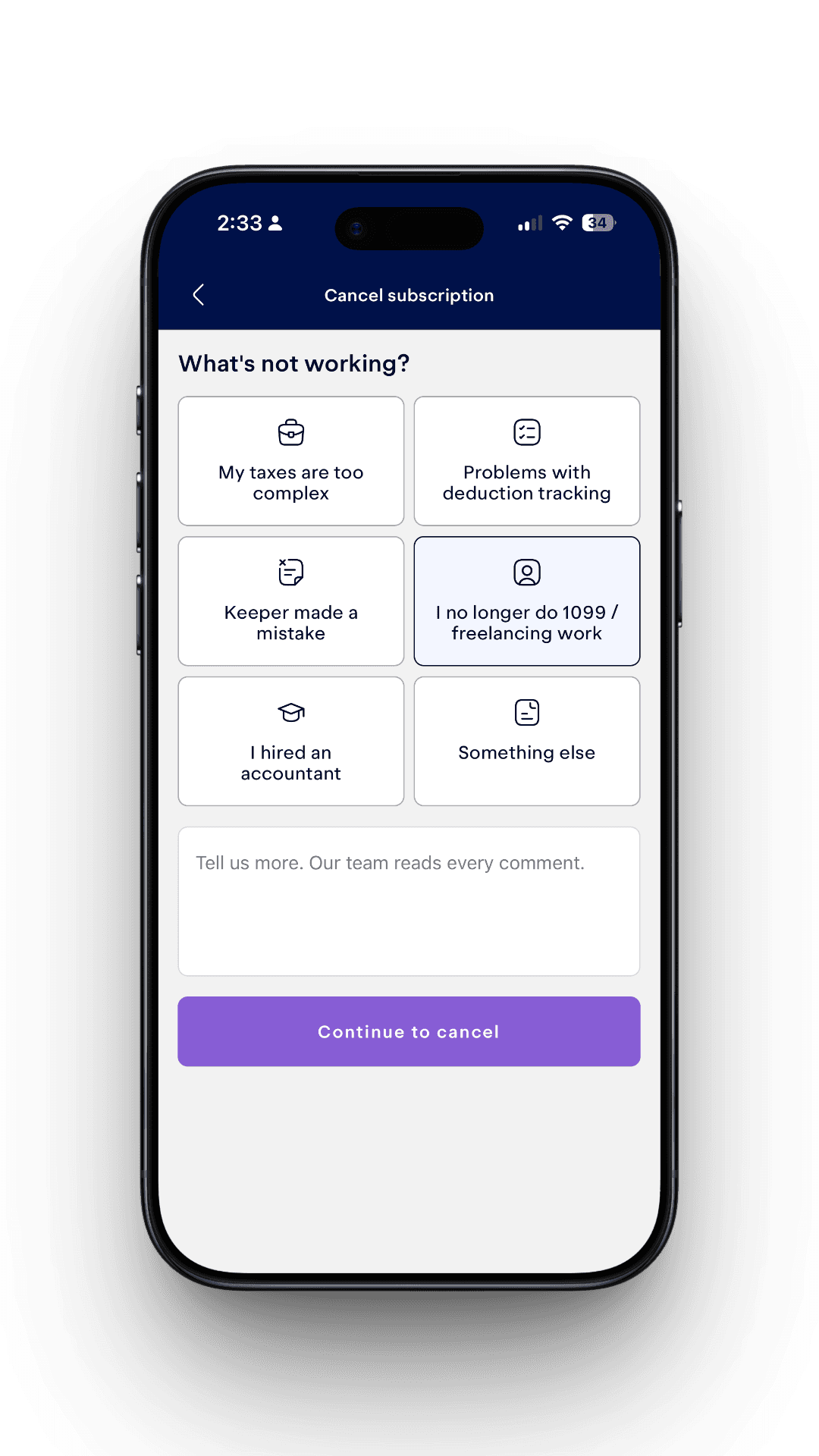
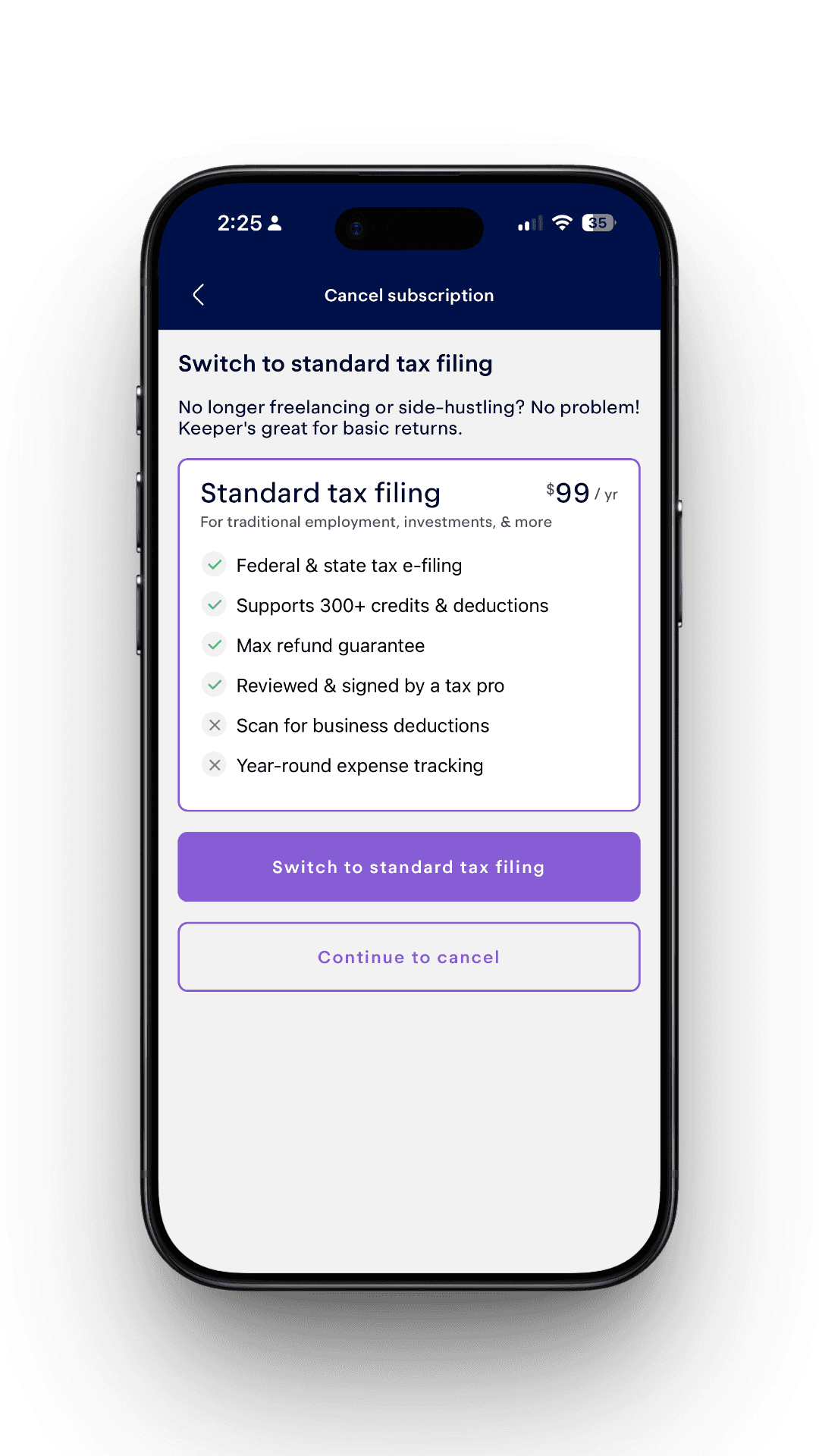
Retention Screens
I implemented multiple retention paths, each guarded by eligibility checks:
- Switch to filing-only for users no longer freelancing
- Upgrade to Premium for complex tax cases
- Complimentary Premium for reported product mistakes
- Payment pause for eligible monthly subscribers
- Direct remediation for deduction tracking issues
If a user is not eligible, the flow falls back to direct cancellation.
State and Analytics
I implemented centralized state to track:
- Selected churn reason and feedback
- Submission and loading state
- Retention versus cancellation outcomes
Analytics are emitted at each step, enabling clean churn and retention funnels without backend inference.
Backend: Cancellation as Infrastructure
All cancellation paths funnel into a single method:
PaymentService.cancelStripeSubscription()This method handles:
- Immediate cancellation for unpaid or delinquent subscriptions
- Cancel-at-period-end behavior for active subscriptions
StripeAPI interactions- Database and lifecycle updates
Centralizing this logic ensures new churn experiments do not compromise billing correctness.
Stripe and Lifecycle Consistency
Stripe webhooks update subscription state and trigger cancellation emails only when cancellation is newly set.
When churn occurs:
- Subscription status updates in the database
- User lifecycle flags and analytics identity are updated
- Messaging tags remain consistent across systems
Why This Matters
This project reflects how I operate as a senior product engineer:
- I execute product designs faithfully while hardening system boundaries
- I treat billing and churn as infrastructure, not UI
- I centralize high-risk logic to prevent long-term maintenance debt
The result is a churn system that supports retention without sacrificing correctness or user trust.